Google Search Console Errors: What to Do When You Find Them
Google Search Console (GSC) is a free tool that helps you monitor your website’s performance to identify and fix any potential problems with Google ranking and technical details of your site’s crawling and indexing process.
It is a must-have for any marketer or webmaster if organic search and organic traffic are vital for your website. It makes it easier to understand what Google thinks about your website and how you can improve its performance in search results by fixing issues such as mobile usability and index coverage problems.
We’ve put together the list of some common error reports, as well as how to determine what might be causing each error and, in most cases, how to correct it quickly.

Want to improve your SEO performance? This article will give you a firm understanding of how the Index Coverage report can help you fight bad user experience.
Read also: Top SEO Tactics for your Small Business SEO success (+extra tips)
In this article:
What is the Google Search Console Index Coverage report about?
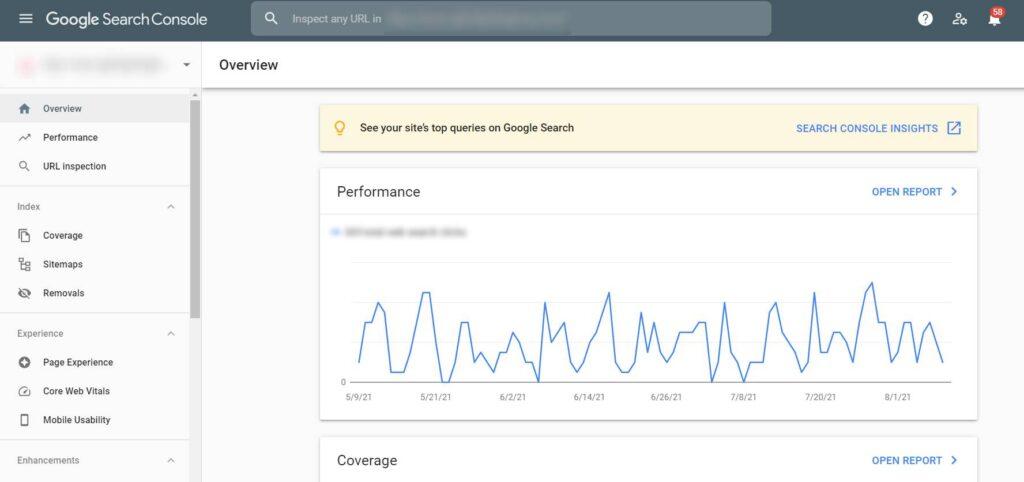
Google Search Console Index Coverage report tells you how many pages in your site are indexed and ranked by Google for specific keywords or keyword phrases.
The index coverage reports on the search console tell us which of our sites have been indexed, with a rank if applicable, to help optimise SEO efforts over time based on any changes from algorithm updates.
The Google Search Console Index Coverage report is a tool to help you understand how well your site content, products and services are indexed by the search engines. It’s categorised into four statuses:
– Valid;
– Valid with warnings;
– Excluded – excluded from indexing due to low quality or relevance of page content for SEO purposes (possible duplicate pages found);
– Error – errors encountered during the crawling process.
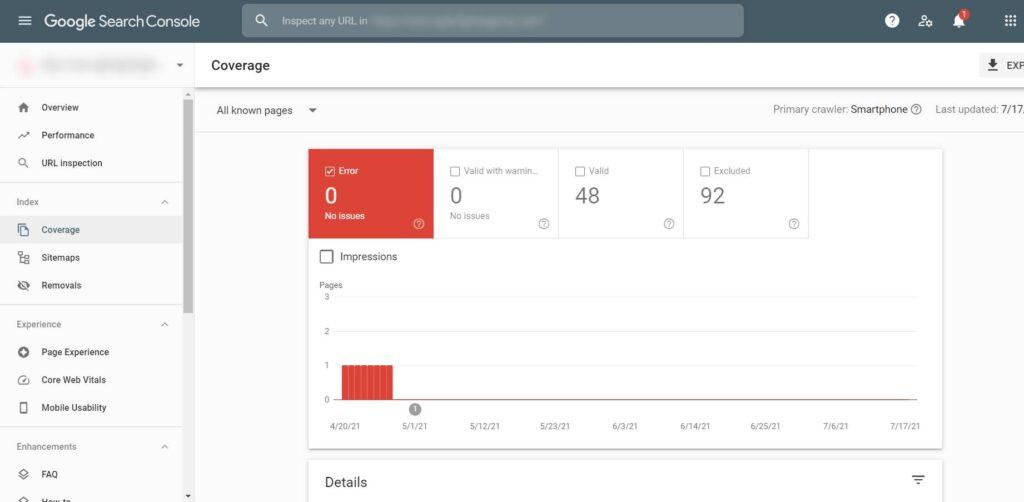
Explanation of Google Search Console Index Coverage report
This screenshot shows what our website looks like in the Google Search Console Index Coverage report right now. The bigger your website and blog get, the more numbers and technical issues would appear in the report.
You can find your Index Coverage report by:
1. Log on Google Search Console from here – https://search.google.com/search-console/
2. Choose the right property (if you have more than one).
Note: If you still don’t have one, you can click on the “Search property” menu and then use the “Add a property” option.
3. Click Coverage under Index in the left navigation.
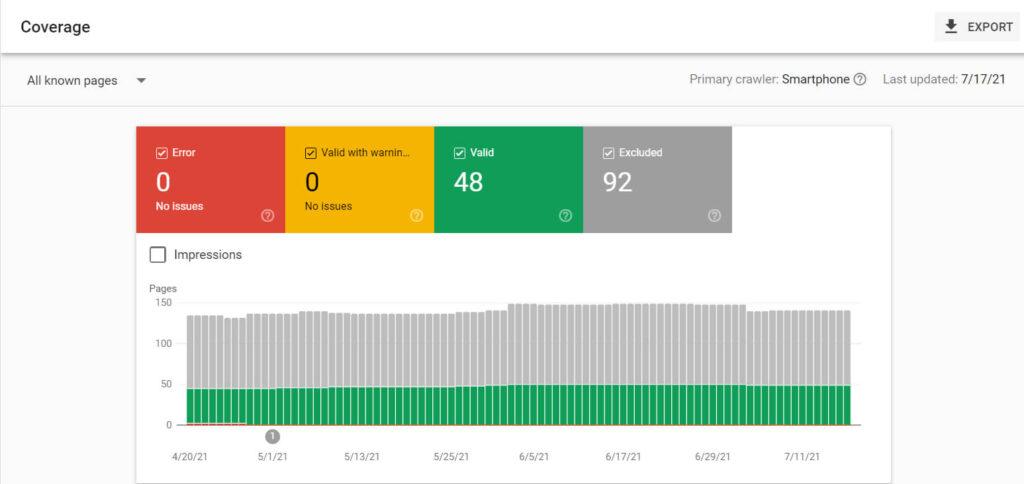
How to fix Google Search Console errors – Google Search Console Index coverage report screen
Types of Google Search Console Errors
This post will go over the most common issues you may find when using Google Search Console. The list comes from Google’s official documentation found on their website, and a summary of what to do in each situation is provided below.
Valid URLs
All pages with a valid status have been indexed.
Submitted and indexed
You submitted the URL for indexing, and it was indexed shortly. The process of submitting a website to be included on Google’s search engine is as simple as entering your web address into the submission form.
Fix: No action is needed here.
Indexed, not submitted in sitemap
The website was found by Google and indexed. We recommend submitting all important websites and pages using a sitemap file to get discovered. This is primarily a must-do for both new websites and larger websites.
Fix: Create an XML sitemap file where all URLs that need to be indexed exist. Verify these URLs that need to be indexed, and if not, make sure you implement the <meta name=”robots” content=”noindex” /> directive and optionally exclude them in your robots.txt.
The XML sitemaps are extremely valuable for larger sites when divided and structured correctly. Make sure you don’t have XML sitemap issues.
Valid URLs with warnings
Google has a clever way of indexing pages blocked by robots.txt files, simply because someone else links to it or the page is indexed from another site with less strict security rules. There are two types of valid URLs with warnings:
– Indexed, though blocked by robots.txt;
– Page indexed without content.
Indexed, though blocked by robots.txt
Google seems to have found a way around your robots.txt file, so they are now indexing these URLs that you never wanted them to see in the first place. Some pages that Google wouldn’t have indexed found links to these URLs, so they went ahead and did it anyway.
Fix: With the robots.txt tester, you can confirm that your page is being blocked from indexation and identify any broad rules blocking it by running a test to see how many pages show up in Google search results when searching for “robots text”. You may need to update your robots.txt file and implement the meta robots noindex directive. Note – you should try to avoid sending mixed signals to Google.
Page indexed without content
Inspecting the page, it seems that Google cannot read the content for some reason. The reasons might be either cloaked to Google, or the page might be in a format that Google bots can’t index, like error 403, for example. Suppose you click on “Coverage” at the bottom of this message. In that case, additional information will appear about what is happening with your site and how to fix any problems associated with it.
Fix: Use both your browser and Google Search Console’s URL Inspection Tool to double-check whether these URLs don’t have content. If everything looks fine, just request reindexing. The URL Inspection Tool is created and is used to inspect only web pages, but not any other file types – PDF file, images, CSS files, or videos.
Excluded URLs
These pages are typically not indexed, and we think that is appropriate. These pages often contain duplicate content type issues or blocked content that should be edited on your site instead of including it on a separate page. This may avoid causing more work for Google’s algorithm and the user who may find this duplicated information irrelevant.
Excluded by ‘noindex’ tag
Google is a search engine and the world’s most popular browser. Google indexes web pages with noindex tags on them, unlike other browsers that don’t index those pages with this tag. To confirm if your page has this directive or tag, use Google as you would in any other situation. Use Google’s search operator – “site:” with the exact page URL. Then check for “noindex” anywhere within the response body or headers of your browser window.
Fix: To avoid missing essential URLs, make sure that you don’t have any in this overview. If there are links with noindex directives on them, but they’re still showing up as indexed pages after a URL inspection, check your page’s source code with Chrome dev tools for the word “noindex”. Then remove the directive in Google Search Console, select inspect the URL using the URL Inspection tool and then choose Request indexing. Double-check whether or not these other web pages contain internal links pointing back into those without an index on their end – you wouldn’t want people to be able to find your site while it’s hidden.
Blocked by page removal tool
It seems like there’s a block on this page by URL removal request. If you are the verified owner of your site, or if someone else is trying to get rid of something they posted here. Maybe Google will come back and index these pages after an additional 90 days period has elapsed, but only time will tell. If you don’t want the page indexed, use ‘noindex’, require authorisation for Google to view it, or remove the page from your site.
Fix: First, check if someone at your company hasn’t asked Google to remove this page with their removal tool. Google will need to be told that it cannot index these URLs. The information should not show up on Google for 90 days, and the robots directive needs to go in place as soon as possible so it can recrawl before those 90 days pass by.

Blocked by robots.txt
This page was blocked to the Googlebot with a robots.txt file, at least until they can find another way in. You may have noticed that this means it’s not indexed on their site yet, but do note this does not mean you’re safe from being found by them elsewhere. Suppose all the information about your website is removed or hidden away without linking back to what you want to keep private. In that case, there won’t be any risk of accidentally having something indexed and published for everyone through search engines.
Fix: Just go through the list of URLs listed in this overview and make sure there aren’t any important ones.
Blocked due to unauthorised request (401)
The page was blocked from Googlebot by requesting authorisation. Audit tools like Screaming Frog SEO Spider and SiteBulb can help you scan your site in bulk and identify such pages.
Fix: If you want Googlebot to crawl such a page, either remove the restrictions or allow the bot to access your content. Both internal and external link sources could lead to an SEO issue like this one if they’re not taken care of.
Crawled – currently not indexed
The page was crawled by Google but not indexed. It may or may not be included in the index for several reasons – no need to resubmit this URL for crawling. If you see this, optimise your page so Google will index it. A good experience for the user and accurate content is necessary to keep them coming back. Google knows about the URL but hasn’t found it essential enough to index. But what if this site had many internal links and was complete with quality content instead of thin content?
Fix: Try to reduce the list of essential URLs and pages from this overview. If you do find important URLs here, check when they were crawled. If an URL has enough internal links to be indexed, but it’s still not, try to improve the page with more fresh content. If, for any reason, you decide to remove the page, make sure you use the URL removal requests tool.
Discovered – currently not indexed
Google found a page on the site, but it hadn’t been crawled yet. You have a poor internal link structure. Typically Google wanted to crawl that URL, but it was considered that this would overload their servers, so they rescheduled their next crawl for when there’s room (or more ‘crawl budget’) to avoid overloading the process. This is why you won’t see any data from the last crawls.
Fix: Too many URLs and not enough crawl budget, Google might not be spending as much time on it. Your website either doesn’t have the authority or has pages with high load time, or is often unavailable – all reasons that will make the crawl process more difficult. Again, try to improve your internal link structure. You can expect a bigger crawl budget over time.
Alternate page with proper canonical tag
This page is a duplicate of the original, canonical version. A canonical tag is a signal to the search engines that can help them prioritise and consolidate all of your links. A common example are pagination URLs, eg: mywebsite.com/category/page-1, /page-2, etc.
Fix: Change the canonical to self-referencing if these pages shouldn’t be canonicalised. Suppose you see an increased amount of pages in this overview more than the increase in indexable pages. In that case, you could potentially be dealing with poor internal link structure or crawl budget issues. To check if you have crawl budget issues, you can perform a server log files analysis. It’s not that easy to understand the details in the server log files and get them – you should search for expert help.
Duplicate without user-selected canonical
It seems that there are duplicate pages for this topic. The copy you’re looking at is not the canonical one, and we believe Google has chosen a different page to be authentic. If you inspect Google’s search results, it will show what they have deemed as most accurate.
Fix: To bring your webpage up in search engine rankings, you must start working on your most valuable URLs (usually your ‘money’ pages). You can do this by adding canonical URL tags and using meta robots tags or X-Robots-Tag HTTP headers if these should not be indexed at all. When Google indexes a page, they may even show you their preferred version of the URL through their URL Inspection tool.
Duplicate, Google chose different canonical than user
This page duplicates another URL, and Google has indexed it instead. We recommend marking this as canonical, explicitly telling Google to only index one version. Google takes into account many factors when it selects a canonical and may choose different canonicals on multi-language sites with highly similar pages and thin content.
Fix: Use the URL inspection tool to learn which canonical Google has selected as the preferred one and see if that makes more sense. For instance, they may have a different canonical because of their links or content.
Not found (404)
This page returned a 404 error when requested. Nobody likes accessing broken links. Google discovered this URL without any explicit request or sitemap. It is possible that the site’s content was deleted and now reappears in another place online, but it also could be due to other circumstances such as links from other sites linking back to old pages of your blog which no longer exist anymore; there would not be much point for Googlebot wasting time with these URLs at all (unless you have some precious information hidden within them). Google stated that 404 responses are not a problem if intentional.
Fix: Make sure there are no important URLs among the ones listed in this overview. If you find an important URL, restore its contents or put a 301 (permanent) redirect to a more relevant alternative. If not redirected appropriately, these URLs will come off as soft 404s.

Page with redirect
The URL has a redirection. Clicking on the link takes you to a different URL, and for this reason, it can’t be indexed.
Fix: There is nothing you can/should do here unless the redirect is not intentional, then you should remove it.
Soft 404
The page request returns what we think is a soft 404 response. 404 simply doesn’t mean a negative impact on your website’s ranking. This means that it does not return an error code for “not found” pages but instead provides the user with a friendly message and sometimes links to other related content on your website if available.
Fix: If you’ve found any 404 errors on your website, please make sure they return a proper HTTP status code. If the URL is not broken or if it simply does not exist at all, then you need to fix that.
Duplicate, submitted URL not selected as canonical
Google was unable to index your content because of duplicate URLs, and you can fix this by picking one URL as the “canonical.” If Google thinks that another URL is a better candidate for canonical, it will not index this URL.
Fix: Check your canonicals properly and add proper canonical tags that point to the preferred version of your URLs.
Blocked due to access forbidden (403)
Googlebot is a bot that crawls the internet and indexes pages. It never provides credentials, so it should not be given an error for requesting them. This error should either be fixed, or the page should be blocked by robots.txt or noindex.
Fix: Make sure that Google has access to URLs you want your site to rank with. If any of the other URLs are listed under this type of issue, it might be best if you just apply noindex (either in HTML or HTTP header).
Blocked due to other 4xx issue
The server encountered a 4xx status code not covered by any other issue type described here. Google couldn’t access these URLs because they received an unusual response code. This could happen when the URL is malformed, which returns a 400 error instead of 404 or 401.
Fix: If these URLs are important to you, investigate what’s going on and take action. You can also add them to an XML sitemap.
Error URLs
Server error (5xx)
Your server returned a 500-level error when the page was requested. An error 500 is the most common server error. A 5xx-level response code means that Googlebot couldn’t access your URL, and as a result, it could not complete its task of cataloguing it for future visits to those seeking out information on this topic.
Fix: There are many reasons why a URL might return a 5xx status code. All of them, however, mean poor user experience. Often, these errors only last for a while because the server is too busy to process all of its requests at once. Investigate particularly which error was returned by checking out what HTTP status code it has in the response headers when looking through your browser’s developer tools. Then take the appropriate action to fix your page.
Redirect error
When you move or remove a page on your site, it’s best to set up a 301 redirect to tell the web browsers that the page has moved and direct them to its new location. The problem appears when your redirects are not up to date.
For example, you deleted a page and redirected it to another URL which you also deleted later on but you didn’t update the original redirect. Such mistakes lead to a redirect chain or a redirect loop.
Fix: To avoid redirect errors, review all your links and make sure all redirects are valid and up to date. There are good browser extensions that can help you identify when a page has been redirected or has multiple hops from the original destination. Avoid redirect loop, redirect chain, and redirects to too long URLs.
Submitted URL blocked by robots.txt
There is a page submitted for indexing, but it is blocked by the site’s robots.txt file.
Fix: The robots.txt tester is a great way to quickly determine if any overly broad rules have blocked your site’s indexation in the file or even some pages on your website that you may have forgotten about. To avoid your site being blocked in search engines, you need to ensure that your essential URLs are unblocked through the robots.txt file. To find this, select a URL and then click on the test robots.txt blocking button on the right side of it. Make sure that you’ve removed these URLs from the XML sitemap.
Submitted URL marked ‘noindex’
You submitted this page for indexing, but the page has a “noindex” directive either in a meta tag or HTTP header.
Fix: If for some reason, there are essential URLs listed as “Submitted URL marked ‘noindex’, you must remove the robots.txt or HTTP header noindex directive. You can use the URL Inspection tool to validate the error.
Submitted URL seems to be a Soft 404
You submitted this page for indexing at some point, but the server is now returning a blank or nearly blank page. What’s going on? These are often empty product category pages, empty blog category pages, empty internal search result pages.
Fix: If you take a look at your website and find 404 errors, make sure that the pages return an HTTP status code of 404 when they are accessed. Check on a URL level. If these URLs aren’t returning error codes but instead showing up because their content is outdated or incorrect, then please correct them so people can get accurate information from your site.
Submitted URL returns unauthorised request (401)
These URLs are inaccessible to Google because they received a 401 HTTP response upon requesting them. This typically happens for staging environments that have been made unavailable with HTTP Authentication.
Fix: If you find any important URLs in this overview, make sure they are not visible to Google. If your website links to password-protected content (for example, you have a staging website that is password protected and you forgot to remove a link to it on your production website) it would likely cause serious SEO issues. Your crawl budget may be affected as the search engine attempts to crawl these URLs repeatedly.
Submitted URL not found (404)
For some reason, you may have submitted an already deleted URL for indexing. Sometimes, a page needs to be removed (creating a 404). This is okay, and it should not affect your rankings. For example, you might draw an old blog post that has received no qualified traffic or links or just delete something like discontinued products from the product line with no equivalents.
Fix: Sometimes, a 404 error simply states that the URL belongs to content that has been moved or deleted. If this occurs and there’s no compelling reason for Googlebot to keep looking in these pages, it should be fixed by adding 301 redirects to a relevant alternative, so it doesn’t get caught up on dead-end links.
Submitted URL returned 403
The submitted URL requires authorised access. You submitted these URLs through an XML sitemap, but Google was not allowed to access them and received a 403 HTTP response. If this page should be indexed, please make it publicly accessible. Otherwise, do not submit this for the indexing process as Google does not have the authorisation credentials.
Fix: If these URLs should be available to the public, provide unrestricted access. Otherwise, remove these URLs from the XML sitemap.
Submitted URL has crawl issue
This error indicates that you submitted a URL through your XML sitemap, and Google encountered an unknown problem when requesting it. Often, errors in this overview are temporary and receive a 404 error later upon checking again. These pages can slow down crawl time.
Fix: To figure out what’s happening, you can use the browser URL inspection tool. If that works, try to investigate on your own what happened. It might be a temporary issue, but still, keep an eye on it.
Submitted URL blocked due to other 4xx issue
The server returned a 4xx response code not covered by any other issue type. This is most likely due to an error with your page and should be fixed before submission or re-submitted after fixing the problem.
Fix: If you are experiencing problems with the 4xx issue, try fetching these URLs using the URL inspection tool to see if you can replicate them. If so, investigate what’s going on and fix it.
We aim to provide you with insightful articles, SEO topics, and data-driven research, so make sure to stay in touch with us. Thanks for being a loyal reader.
Still experiencing indexing issues? Then you may need a technical SEO agency to improve your organic search traffic. Please don’t hesitate to contact us for assistance.

Our commitment to excellence is underscored by our recognition as a Top Technical SEO Agency in London for 2026.
Frequently Asked Questions
What are the most common Google Search Console errors?
The most frequent errors include 404 (page not found), 5xx server errors, redirect errors (redirect chains or loops), mobile usability issues, crawl anomalies, and indexing issues where Google discovers pages but chooses not to index them. The Coverage report in Search Console provides a breakdown of all errors affecting your site.
How quickly should I fix Google Search Console errors?
Prioritise by impact. Server errors (5xx) and errors on important pages should be fixed immediately as they prevent indexing. 404 errors on pages with existing backlinks or traffic need prompt attention via redirects. Soft 404s and minor crawl anomalies can be addressed in your regular maintenance cycle. Check Search Console weekly at minimum.
Do Search Console errors affect AI search visibility?
Yes. Pages with crawl or indexing errors are invisible to both traditional and AI search engines. If AI systems cannot access and index your content, it cannot be cited in AI-generated responses. Maintaining a clean, error-free crawl profile is foundational for both traditional SEO and AI search visibility.
How do I fix ‘Discovered — currently not indexed’ in Search Console?
This status means Google found your URL but chose not to index it yet. Improve the page’s quality and uniqueness, add internal links pointing to it from authoritative pages, ensure it’s included in your XML sitemap, submit it via the URL Inspection tool, and verify it provides genuine value that isn’t already covered by other indexed pages on your site.

Related
Articles